HBase: Wide-Column Storage Database
Contents
Features
HBase is a column storage database that can have many different columns, and it is allowed for columns to contain no values. So HBase is a good way of representing sparse tables.
HBase supports simple operations including insertion, searching and deletion, while joining between tables are beyond its scope. You can see HBase is a type of NoSQL database. There is only one datatype in HBase, which is byte array byte[]. HBase runs on top of Hadoop Distributed File System and relies on ZooKeeper for high-performance coordination.
Each element in a HBase table can be identified with the tuple of column family, column qualifier, row key and timestamp version. Column families are the logical and physical grouping of columns. The row keys and timestamp versions are stored within each column family separately.
Hbase is an open-source alternative of BigTable which is developed by Google. Google uses BigTable to store the newly generated websites, which contain a large portion of sparse data and require frequent insertion into the existing tables. Hence, the key words sparse data and frequent insertion totally reflect the advantage of HBase. Also, HBase is mainly used for development configuration, not in production scenarios.
Notice that with column family, column qualifier and row key, we can locate a cell, which contains multiple versions. Each version contains a value and a timestamp. If we view HBase as a mapping from (column family, column qualifier, row key, version) to data entries, HBase can function as a type of distributed Key-Value storage.
Wide Column Databases vs Relational Databases
For relations databases, when we are going to read some records, it will load all columns of targeted records into a page (page is the unit of system I/O), causing that unwanted columns take up a lot of space in pages. However, for HBase, it first selects the needed columns and then searches row keys within those columns. The reading efficiency of wide-column database outperforms relational databases. Moreover, when we add a new column, the entire table in relational databases gets affected, while in HBase operations with respect to a column only change rows associated with that column.
There is another popular wide-column database called Cassandra. Learn more at Cassandra-vs-HBase.
How It Works
Architecture
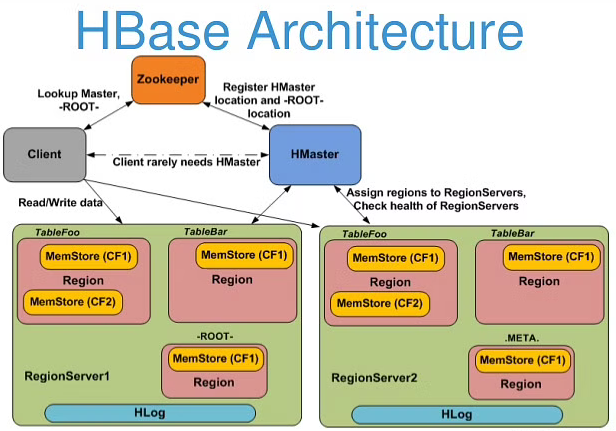
HBase is made up of three main parts: HMaster, which assigns regions of data to the region server. Region Server, which handles requests from users for data input and output. ZooKeeper, which manages and tracks the data as it flows across region servers.
The HMaster administrates and maintain the partition information of HBase systems, such as how a table is separated into different Regions and where can a client locate the Regions. HMaster is also responsible for load balancing for Regions.
Region servers store and maintain the data assigned from HMaster. And they process the I/O instructions sent from clients.
Clients never directly communicate with HMaster. When a client needs to know the location of a specific table, it sends a query to Zookeeper and gets the information about related Region servers.
Storage of Region Servers
For each HBase table, the rows are sorted by the dictionary order of row keys. The tables are partitioned into different Regions according to the row keys. So a Region can be defined by a range of row keys. Every Region has a unique RegionId. So a Region can globally located by a Region Key: Table Name + Region Start Key + Region Id.
Meta Table
The hbase::meta table keeps a list of all Regions in the system and this hbase:meta is stored in a ZooKeeper ZNode. This meta table is a loop up table where client can find the server and region infos via the Region Key.