Google Research: Differentiable Search Index
Contents
Introduction
Information Retrieval (IR) is an important technique that has laid the foundation of development of search engines and recommendation systems. For recommendation systems, it is crucial to retrieve a small pool of candidates from the vast amount of data before predicting the CTR/CVR of each item.
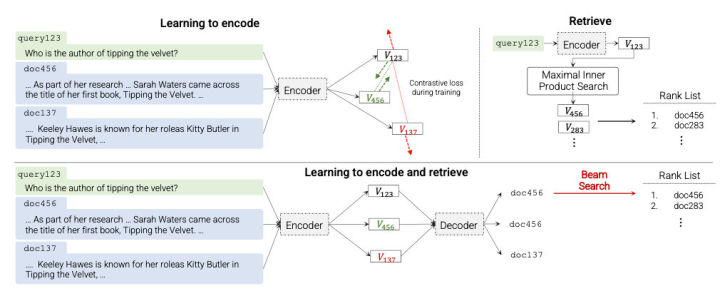
Considering the most popular indexing methods, such as BM25 and Embedding-based Retrieval, the process is to convert the documents into vector space and during retrieval we try to find the document that best matches the query. Therefore, the complexity would always increase with the size of documents. Is there a method that we can store all information about the documents within one single model and map the query directly to the relevant documents with this model? This is the idea of one of Google’s recent papers: Transformer Memory as a Differentiable Search Index (DSI). Arxiv Link
Overall Strategies
With DSI, the processes of indexing and retrieval are unified. When indexing, we feed the embedded sequences of documents into the model and predict their ids. For retrieval, similarly, we input the embedded query to the model and it would predict the id of the closest candidate documents. Note that indexing and retrieval are both included in training process while only retrieval is performed during inference. There are many interesting designs to explore:
Structured Identifiers
Typically, we would randomly assign some integer id to each document as their unique identifier. Suppose we have $N$ documents. For prediction, we need to output a softmax vector with dimension of $N$ to represent the probability of each document. This softmax output layer has long been notorious for its awful computational cost.
However, by using a string identifier, it is possible to view each identifier as a sequence (yes string itself is a type of array!). Suppose we use strings of 6 digits to identify each document. The inference of DSI model would consist of 6 time steps of prediction with each step predicting the probability of digits. Beam search is then naturally used here.
To make the string id more meaningful, DSI proposes to cluster the document embeddings to several categories and assign the element of the document’s string id according to the id of the clustered category. Just like the graph shows. It is obvious that if two ids share a long common prefix, then the two corresponding documents are very similar. In this way, each string id is actually a representation of a prefix tree (trie)!
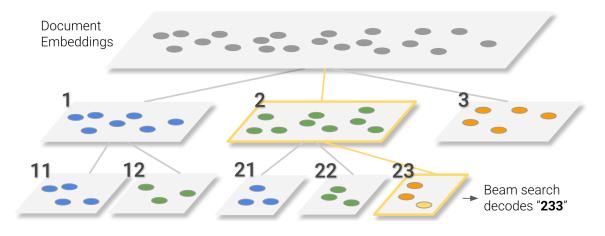
The authors also point out that end-to-end learning of identifiers may become an interesting future work in this area.
Co-training of Indexing and Retrieval
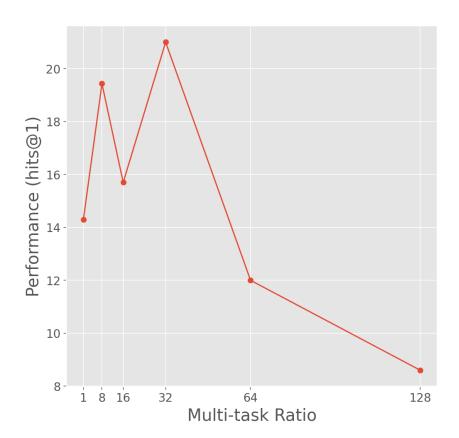
There are two possible training methods for DSI. The first one is to learn indexing from documents (memorization) and then fine-tune the model with query inputs. The other is co-train the indexing task and the retrieval task simultaneously in similar fashion to T5-style co-training [ref]. This is because the retrieval task is actually a down-stream task of the indexing task, which is similar to the scenario in T5. The results of tuning the ratio between the two task losses is following:
Other Settings
The authors have also considered many other aspects of designing this pipeline of information retrieval.
First, how should we chose the indexing method? A mapping from tokens to id is the most straightforward (called Inputs2Targets). The authors propose that we can train the indexing via a Bi-directional formulation. A prefix token is prepended to allow the model to know which direction of the task is being performed in. The results of Bi-directional indexing strategy is slightly worse than the Inputs2Targets strategy.
Then, how should we convert documents into sequences of embeddings? We can use the first K tokens, use a deduplicated set of tokens or use any contiguous K tokens to represent a document. However, the experiments indicate that directly using first K tokens is the best option. Deduplication and removing stopwords don’t help much.