All About AUC
Contents
Definition
A formal definition of AUC is: $$AUC=P(f(x)>f(y)),\ x\sim \mathcal D _{+}, y\sim \mathcal D _{-}$$
where $\mathcal D _+$ is the set of positive samples, and $\mathcal D _-$ is the set of negative samples. Therefore, the metric of AUC can be interpreted as “the probability that a positive sample is wrongly ranked ahead of a negative sample”. AUC can naturally measure the performance of a binary classification model and is thus widely used in evaluating recommendation systems. Also, its resistance against class imbalance is helpful when handling skewed data.
Based on the definition, AUC seems to be suited for evaluating algorithms associated with ranking documents, just like search engines. However, search engines pay more attention to the top-k results than the others, while AUC pays equal attention to the results regardless of the absolute location. NDCG, which is a weighted relevance metric, is better at ranking documents.
While in machine learning related classes, we are often told that AUC stands for the Area Under the Curve, where the curve refers to the ROC Curve. First, let me introduce the ROC Curve - the curve showing the relation between True Positive Rate (TPR) and False Positive Rate (FPR):
$$ TPR = \frac{TP}{TP+FN} $$
$$ FPR = \frac{FP}{FP+TN} $$
Given any threshold $t$ in $[0,1]$, we determine whether a sample is predicted as positive by checking if $f(x) > t$, and then we can derive the corresponding $TPR(t)$ and $FPR(t)$ as functions of $t$. With this parameter $t$, we can easily draw the ROC Curve.
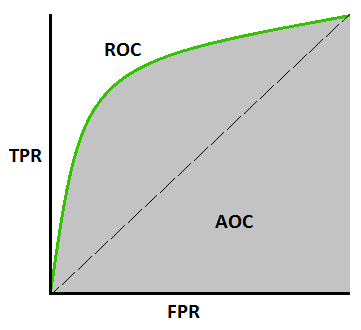
Here is a mathematical proof about the relation between the probability definition and the area definition of AUC:
Let $s_+$ and $s_-$ be the score of a random positive/negative sample. Consider the probability that the $s_-$ lies between $[t, t+\Delta t]$: $$\begin{aligned} & P\left(t \leq s_{-}<t+\Delta t\right) \\
=& P\left(s_{-}>t\right)-P\left(s_{-}>t+\Delta t\right) \\
=& \frac{N_{-}(t)-N_{-}(t+\Delta t)}{N_{-}} \\
=& FPR(t)-FPR(t+\Delta t)=-\Delta FPR(t) \end{aligned}$$ Suppose $\Delta t$ is sufficiently small, then the conditional probability that $s_+$ is bigger than $s_-$ is $$ \begin{aligned} &P\left(s_{+}>s_{-} \mid t \leq s_{-}<t+\Delta t\right) \\
&\approx P\left(s_{+}>t\right)=\frac{\text{# of pos samples predicted as pos}}{\text{# of pos samples}}\\
&=\frac{TP(t)}{P}=TPR(t) \end{aligned} $$ Then, $$\begin{aligned} & P\left(s_{+}>s_{-}\right) \\
=& \sum_t P\left (t \leq s_{-}<t+\Delta t\right) P\left(s_{+}>s_{-} \mid t \leq s_{-}<t+\Delta t\right) \\
=&-\sum_{t} TPR(t) \Delta FPR(t) \\
=&-\int_{t=-\infty}^{\infty} TPR(t) d FPR(t) \\
=& \int_{t=\infty}^{-\infty} TPR(t) d FPR(t) \end{aligned}$$
- Why do we interchange the limits in the last step? It’s because $FPR(t)$ decreases when $t$ goes up. We want the x-axis to be increasing and thus $t$ must be decreasing.
Therefore, the two definitions are completely equivalent. Though, the area definition is more intuitive and more often talked about.
Calculation
Based on the two types of definition, how do we use Python or SQL to calculate the AUC if we are given the labels and predicted scores of samples?
1. Calculation by Area
Based on the area definition, we can divide the x-axis into lots of small intervals and use trapeziums to approximate the area.
|
|
2. Calculation by Reverse Pairs
How do you estimate the probability that a positive sample ranks higher than a negative sample? A very intuitive solution may be
$$ \frac{\text{# pair of samples such that $f(a) > f(b)$ and $label(a) > label(b)$}}{\text{# pair of samples}} $$
And it can be proved that this is actually a maximum likelihood estimator. Therefore, the algorithm is like:
|
|
However, this implementation is not satisfactory due to its two layers of for-loops, which accounts for $O(n^2)$ time complexity.
Actually, we can sort the samples with regard to its prediction value in ascending order, and then find the number of reverse pairs (namely $i < j$ $\land$ $nums[i] > nums[j]$). Therefore, a MergeSort based algorithm can reduce the time complexity to $O(n\log n)$.
Another idea is from the reference blog. Let’s consider a random positive sample. Assume that it is ranked j-th among all positive samples. Then there are $j-1$ positive samples before it. And assume that its ranking among all samples is $r_j$. Then there are $r_j - j$ negative samples before it. So, the probability that another random negative sample lies before this positive sample is $(r_j - j)/N_-$, where $N_-$ is the number of negative samples. Given this, let’s average the probability over all $j$:
$$ AUC = \frac{1}{N_{+}} \sum_{j=1}^{N_{+}}\left(r_{j}-j\right) / N_{-}=\frac{\sum_{j=1}^{N_{+}} r_{j}-N_{+}\left(N_{+}+1\right) / 2}{N_{+} N_{-}}$$
The implementation becomes:
|
|
There is another way of implementing this calculation in SQL:
|
|
Reference
[1] https://tracholar.github.io/machine-learning/2018/01/26/auc.html
[2] https://developers.google.com/machine-learning/crash-course/classification/roc-and-auc